Abstract
A VLM teaches itself to ask better visual questions — harder, more grounded, more diverse — and becomes a stronger questioner without losing its answering ability.
Vision-language models (VLMs) are typically trained as passive answerers, while their ability to actively ask diverse, non-trivial, visual-centric, and grounded questions remains underexplored. Existing visual questioners are bottlenecked by the availability of high-quality training data or the cost of curating it. We show that a VLM can continuously improve itself as a visual questioner without any external supervision. We propose a self-evolving framework that uses a VLM itself as both a proposer and a filter to produce harder, more informative, and visual-centric questions, while maintaining exploration diversity to avoid training collapse. These questions are then used to train the VLM in both questioner and answerer modes. To evaluate the questioner, we introduce an agentic protocol that assesses questions along perception, reasoning, and diversity dimensions. Experiments across various backbone VLMs show that our method substantially enhances the quality and expands the difficulty boundary of autonomous question generation. Under the same budget, our self-supervision is more effective than training on static source data — and the self-evolving questioner remains a competitive or even better answerer.
Overview
A VLM that learns to ask better questions — by proposing, rewriting, filtering, and learning from its own.
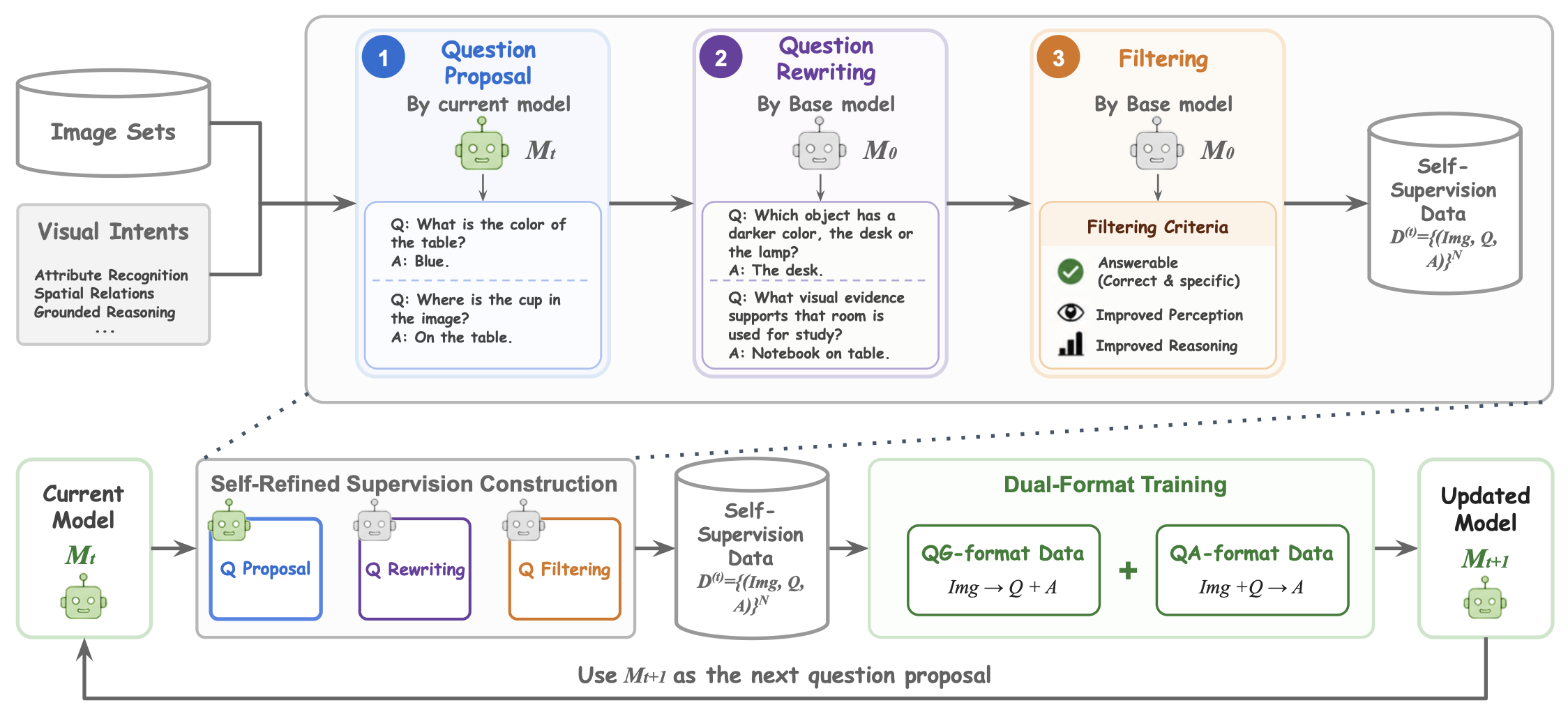
Why it works: harder questions demand richer visual evidence and deeper reasoning, so the model’s own questions become more effective training signal than static data — all with no external supervision, while keeping its answering ability intact.
Evaluation Framework
How do you measure whether a generated question is actually good? We introduce an agentic protocol that goes beyond surface fluency.
Evaluating question quality is fundamentally harder than evaluating answers: there is no single ground-truth question for a given image, and naive metrics (BLEU, CIDEr) reward lexical overlap rather than visual grounding or cognitive demand. We design an agentic evaluation protocol that uses a VLM judge to probe each generated question across five interpretable dimensions.
Five Quality Dimensions
Each dimension is scored on a 0–1 scale by the VLM judge, and the QG Average is the mean across all five. This multi-dimensional score is more informative than a single scalar: a model can improve spatial reasoning while still lacking contextual diversity, and the breakdown pinpoints exactly where gains are concentrated.
Self-Improving Question Quality
Question quality climbs every round — while answering ability holds.
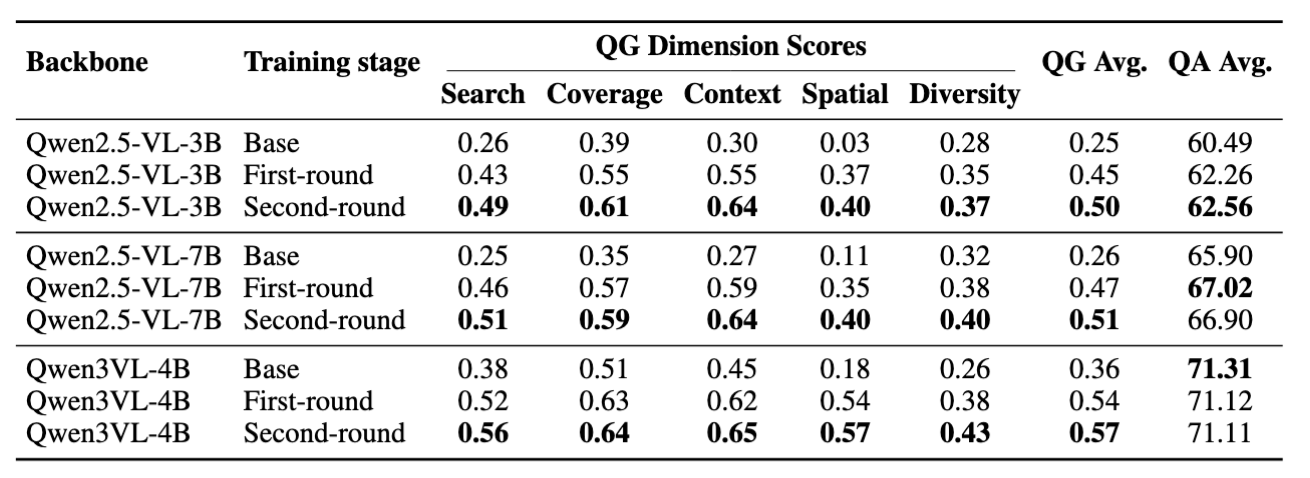
Across Qwen2.5-VL-3B/7B and Qwen3VL-4B, the self-evolving framework consistently lifts question-generation quality. QG average roughly doubles from the base model (e.g., 0.25 → 0.50 on the 3B), with the largest gains on spatial and contextual reasoning. The second round improves over the first — the gains compound rather than saturate.
Key takeaway: better questions don’t come at the cost of answering. Dual QA+QG training keeps QA accuracy competitive (even improving on several benchmarks) while the model becomes a markedly stronger questioner.
Do Better Questions Help Supervision?
With answers held fixed, better questions alone make better training data.
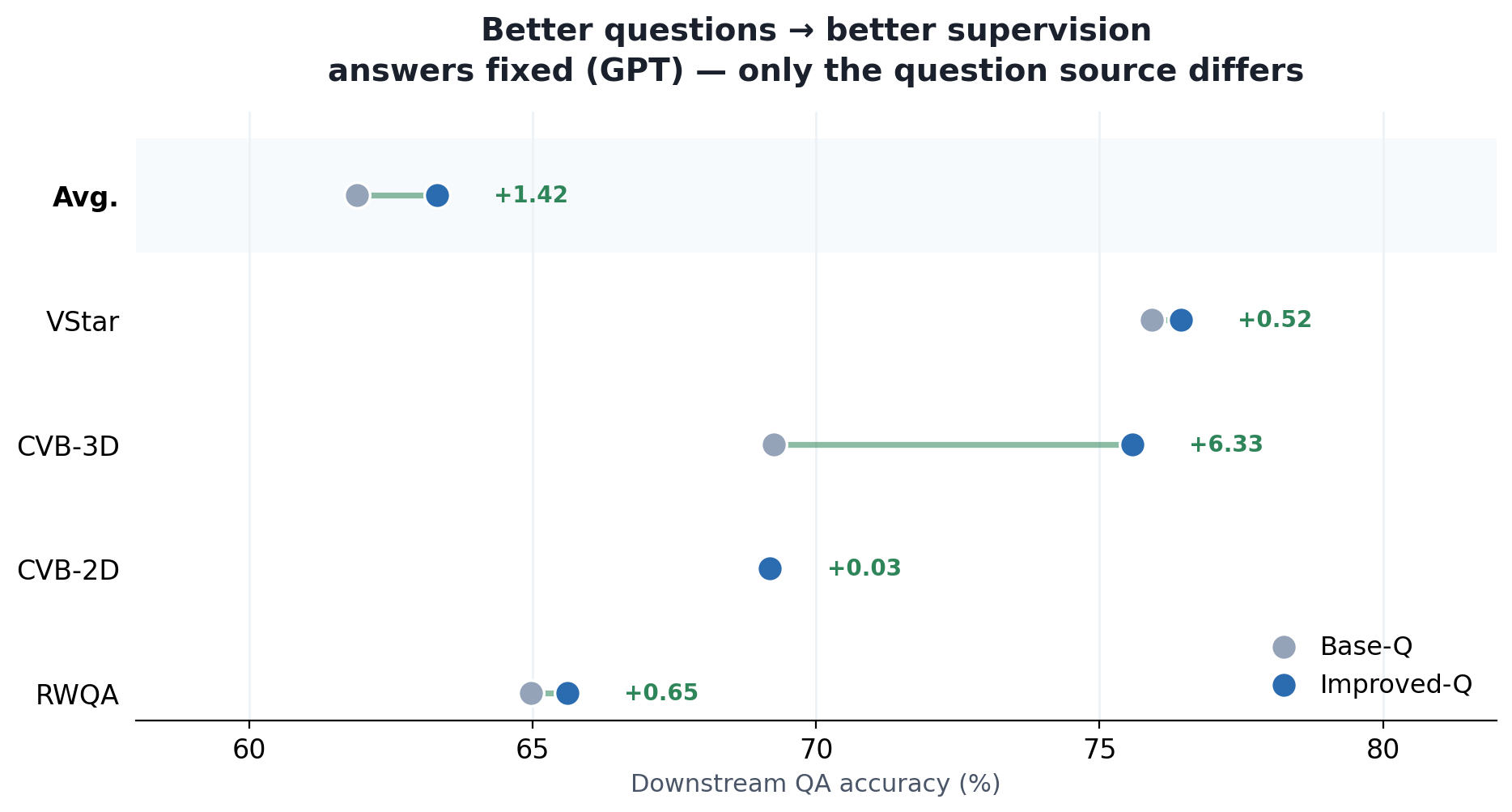
Are better questions useful beyond the questioning task? We build two QA training sets that differ in only one thing — whether the questions come from the base model (Base-Q) or the improved questioner (Improved-Q). GPT generates the answers for both, so any difference comes purely from question quality.
Key takeaway: questions from the improved questioner train a stronger answerer — +1.4 average and a striking +6.3 on CVBench-3D. Questions that demand richer visual evidence and spatial reasoning are simply more informative supervision.
Watch the Questions Evolve
From shallow recognition to grounded, multi-step reasoning — on the same image, across self-evolving rounds.



More examples in the paper (Figures 9–10).